Xuanlin (Simon) LiI am a tech-lead research scientist and a founding team member at sudo.ai. I build generalizable algorithms & systems for robotics, across data and learning. Resume (Oct'24) / GitHub / Google Scholar / LinkedIn / Twitter / Email |

|
ResearchI am primarily interested in Embodied AI, Vision-Language, and Robotics. My goal is to build robotic agents with universal, open-world manipulation, perception, and reasoning capabilities that can be efficiently and robustly deployed for real world applications. This is done by scaling up high-quality training data, RL & learning-from-demonstration algorithms, vision-language models, and evaluation benchmarks. During my PhD, I have been a major contributor of the SAPIEN Manipulation Skill Challenge (ManiSkill). I've also lead the benchmark on evaluating real-world generalist robot manipulation policies in simulation (Simpler-Env). Education: PhD, UCSD CSE, advised by Prof. Hao Su, 2021-2025. B.A. Mathematics & B.A. Computer Science, UC Berkeley, 2017-2021; research assistant at Berkeley Artificial Intelligence Research, advised by Prof. Trevor Darrell. (* = equal contribution) |
|
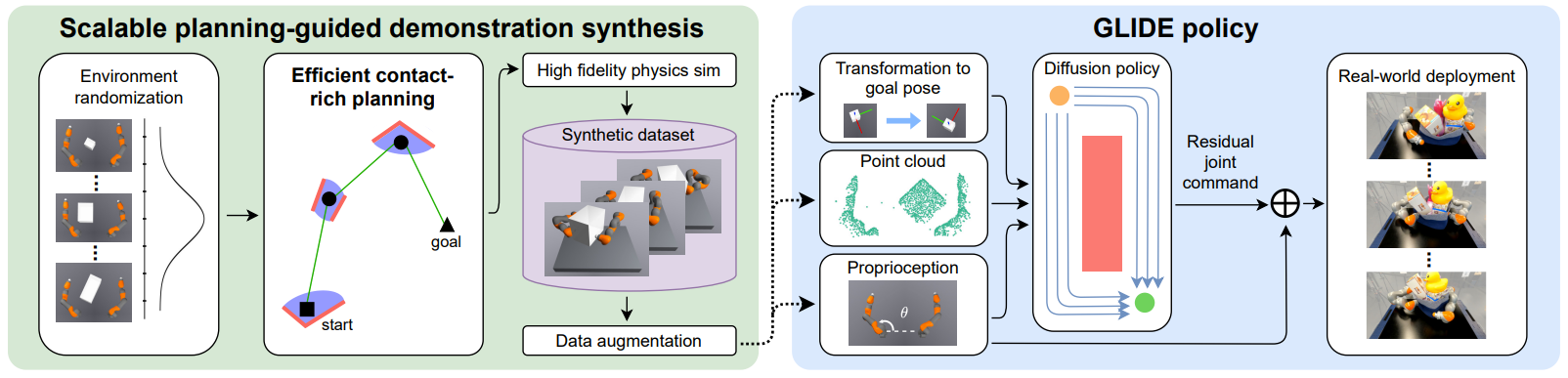
Planning-Guided Diffusion Policy Learning for Generalizable Contact-Rich Bimanual ManipulationXuanlin Li, Tong Zhao, Xinghao Zhu, Jiuguang Wang, Tao Pang, Kuan Fang Preprint paper / website / |
|
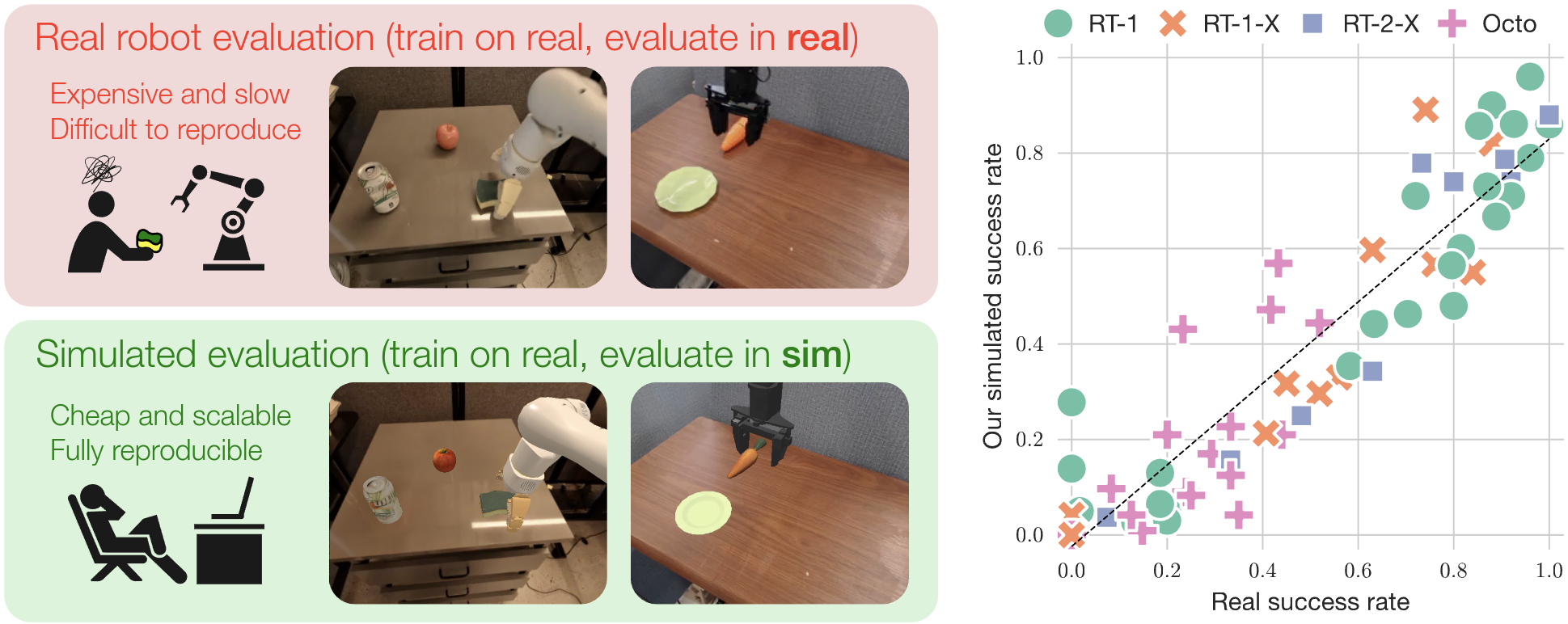
Evaluating Real-World Robot Manipulation Policies in SimulationXuanlin Li*, Kyle Hsu*, Jiayuan Gu*, Karl Pertsch^, Oier Mees^, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su^^, Quan Vuong^^, Ted Xiao^^ Conference on Robot Learning (CoRL) 2024 paper / website / code / |
|
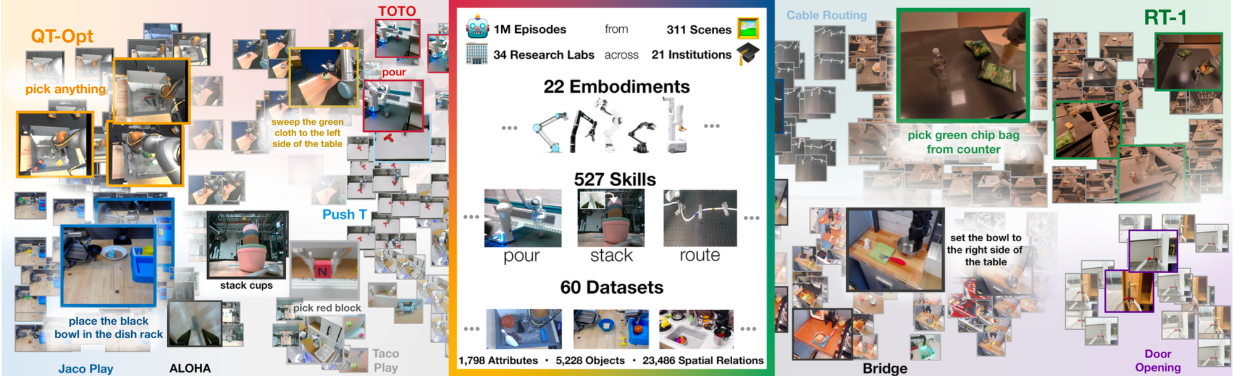
Open X-Embodiment: Robotic Learning Datasets and RT-X ModelsContributor & Author IEEE International Conference on Robotics and Automation (ICRA) 2024 paper / website / |
|
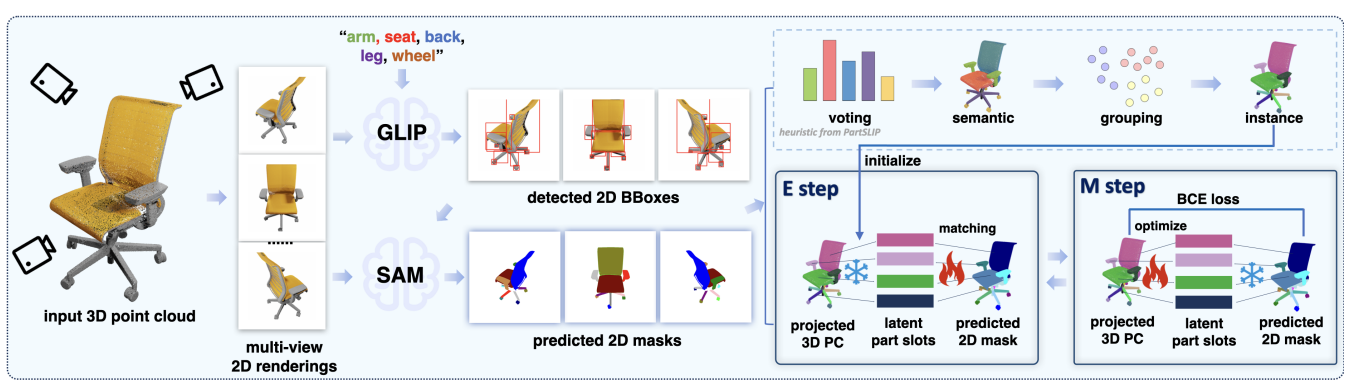
PartSLIP++: Enhancing Low-Shot 3D Part Segmentation via Multi-View Instance Segmentation and Maximum Likelihood EstimationYuchen Zhou*, Jiayuan Gu*, Xuanlin Li , Minghua Liu, Yunhao Fang, Hao Su Preprint arxiv / |
|
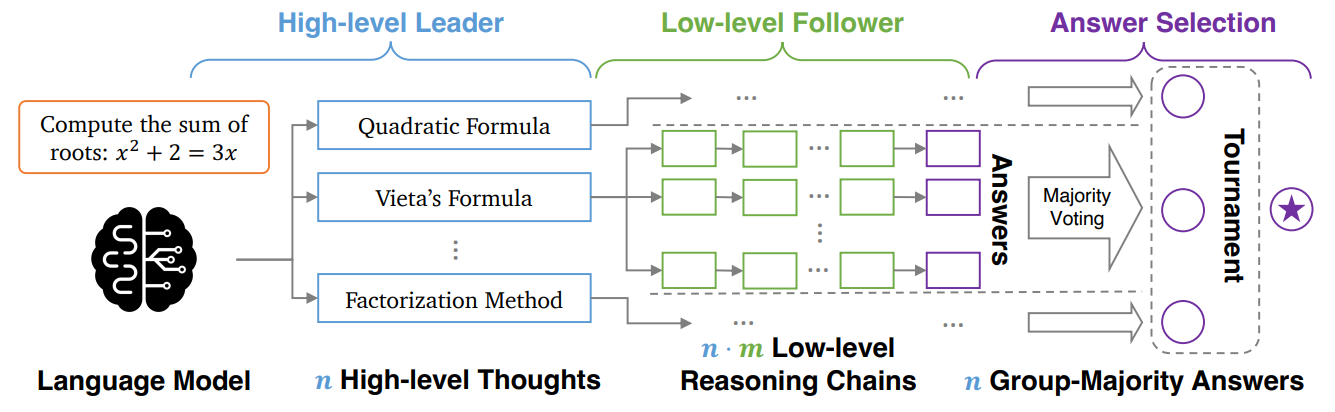
Unleashing the Creative Mind: Language Model As Hierarchical Policy For Improved Exploration on Challenging Problem SolvingZhan Ling, Yunhao Fang, Xuanlin Li, Tongzhou Mu, Mingu Lee, Reza Pourreza, Roland Memisevic, Hao Su Preprint arxiv / |
|
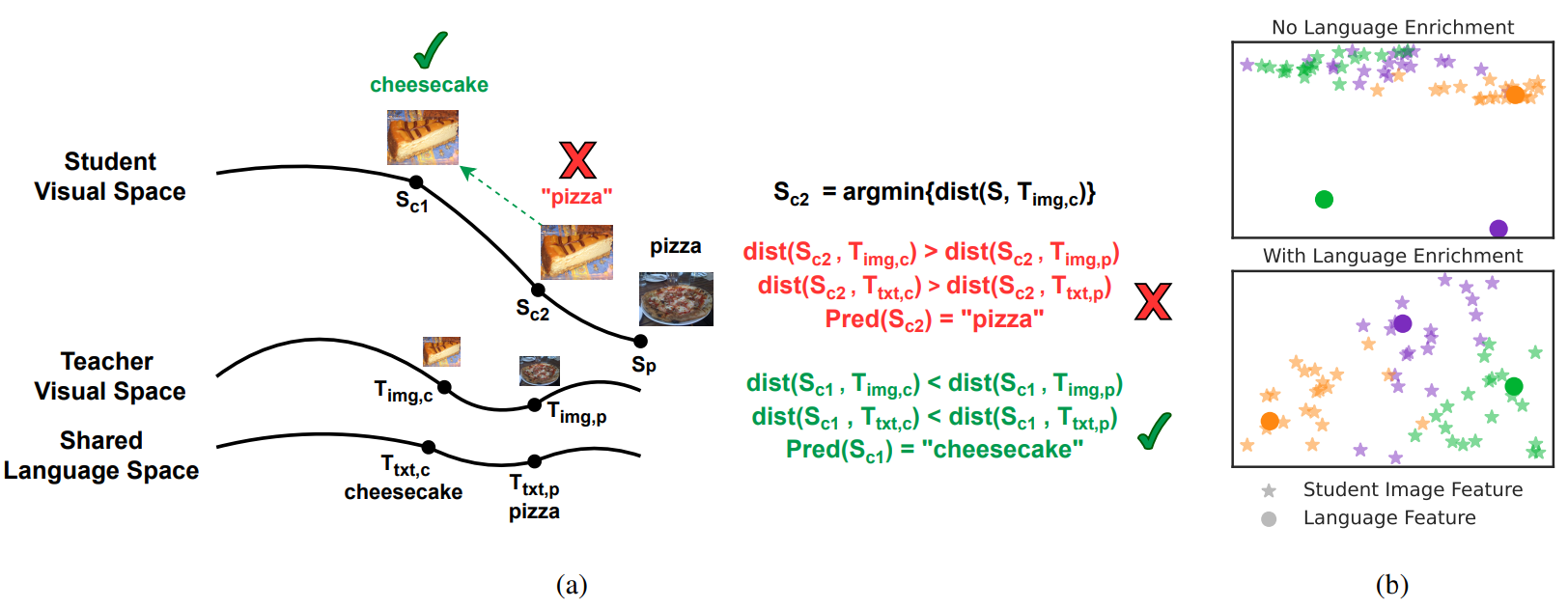
Distilling Large Vision-Language Model with Out-of-Distribution GeneralizabilityXuanlin Li*, Yunhao Fang*, Minghua Liu, Zhan Ling, Zhuowen Tu, Hao Su International Conference on Computer Vision (ICCV) 2023 arxiv / code / poster / |
|
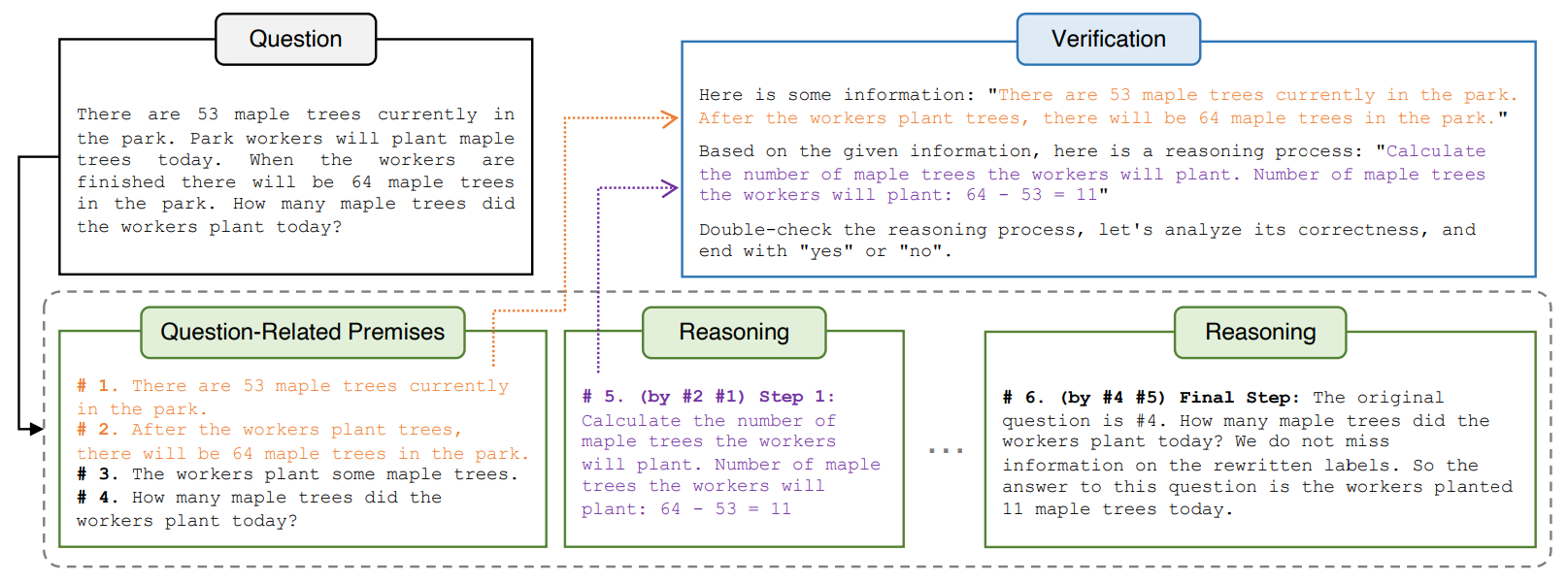
Deductive Verification of Chain-of-Thought ReasoningZhan Ling*, Yunhao Fang*, Xuanlin Li, Zhiao Huang, Mingu Lee, Roland Memisevic, Hao Su Neural Information Processing Systems (NeurIPS) 2023 arxiv / code / |
|
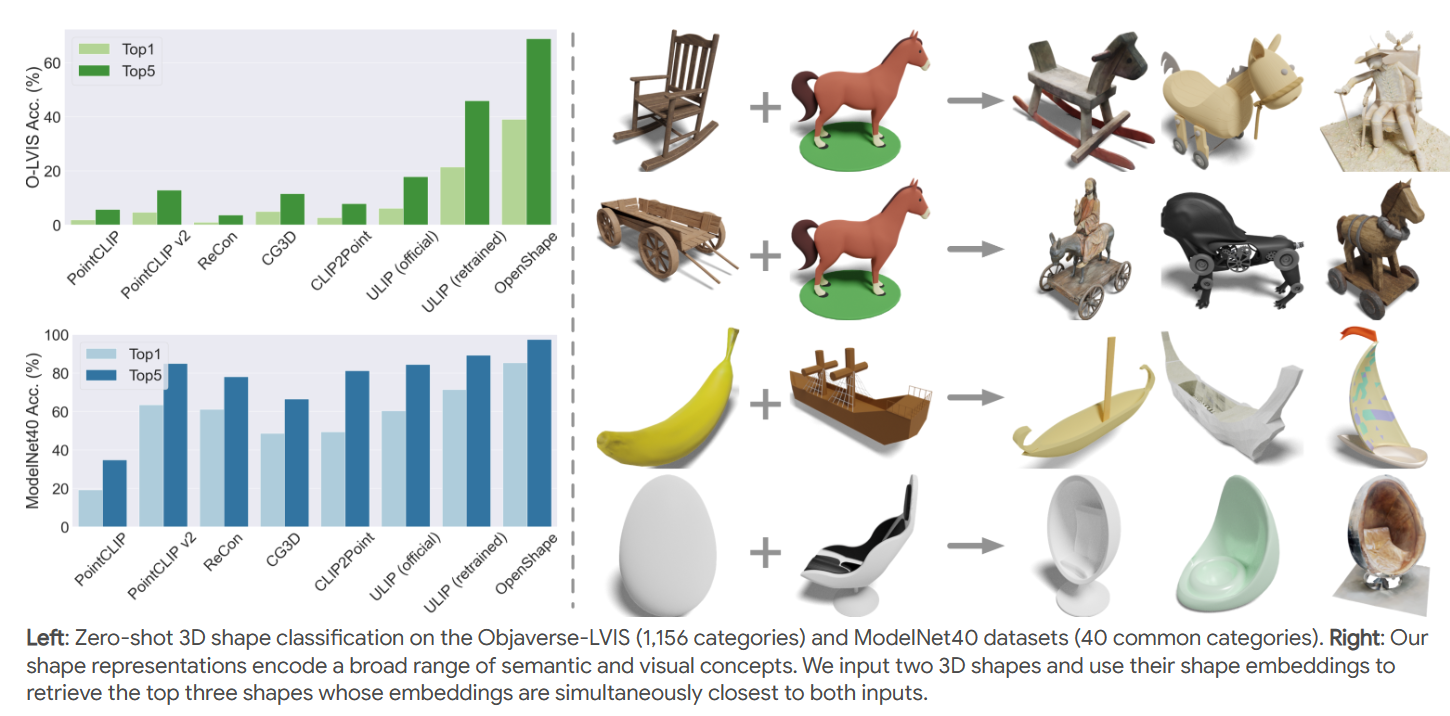
OpenShape: Scaling Up 3D Shape Representation Towards Open-World UnderstandingMinghua Liu*, Ruoxi Shi*, Kaiming Kuang*, Yinhao Zhu, Xuanlin Li, Shizhong Han, Hong Cai, Fatih Porikli, Hao Su Neural Information Processing Systems (NeurIPS) 2023 arxiv / website / code / |
|
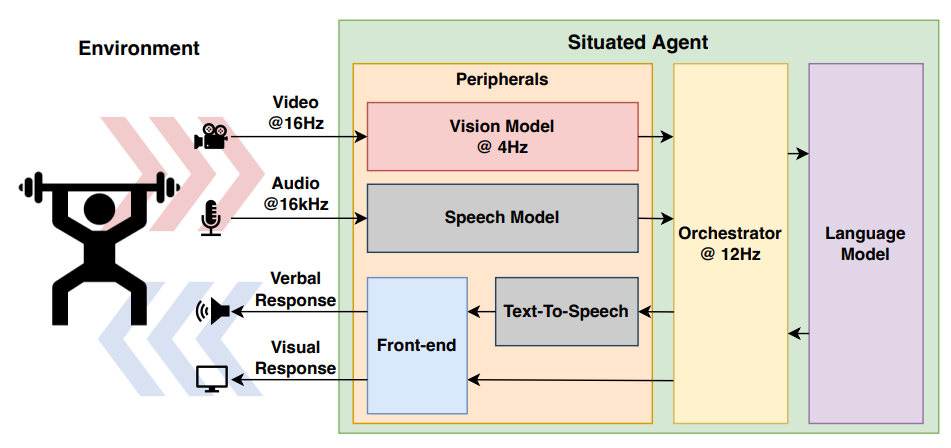
Live Fitness Coaching as a Testbed for Situated InteractionSunny Panchal, Apratim Bhattacharyya, Guillaume Berger, Antoine Mercier, Cornelius Bohm, Florian Dietrichkeit, Reza Pourreza, Xuanlin Li, Pulkit Madan, Mingu Lee, Mark Todorovich, Ingo Bax, Roland Memisevic Neural Information Processing Systems (NeurIPS) 2024 paper / |

|
On the Efficacy of 3D Point Cloud Reinforcement LearningZhan Ling*, Yunchao Yao*, Xuanlin Li, Hao Su Preprint arxiv / code / |
|
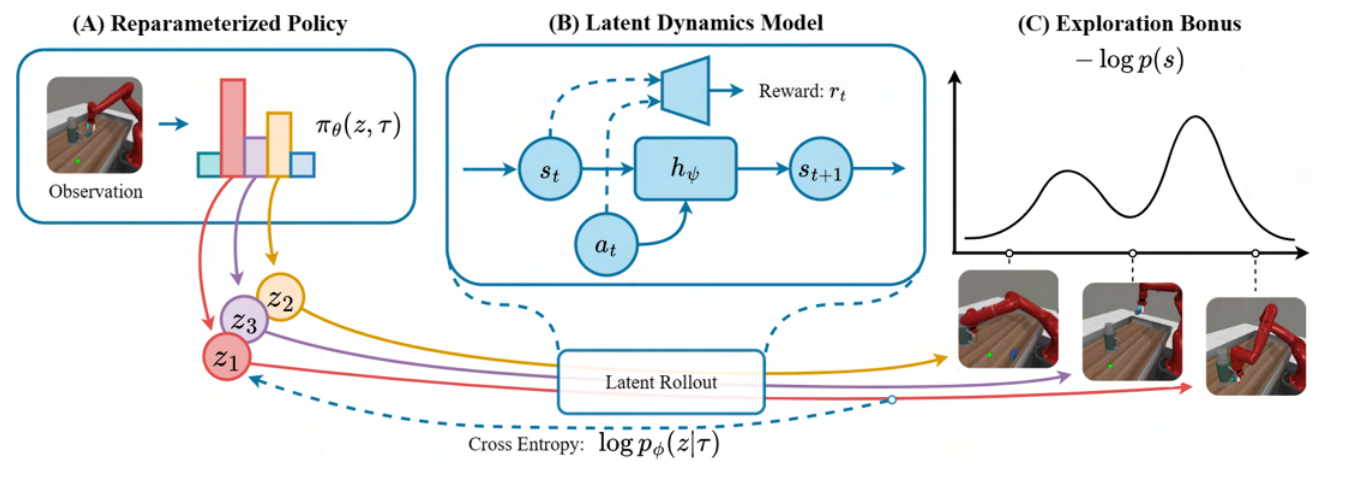
Reparameterized Policy Learning for Multimodal Trajectory OptimizationZhiao Huang, Litian Liang, Zhan Ling, Xuanlin Li, Chuang Gan, Hao Su International Conference on Machine Learning (ICML) 2023 (Oral) arxiv / website / code / |

|
Frame Mining: a Free Lunch for Learning Robotic Manipulation from 3D Point CloudsXuanlin Li*, Minghua Liu*, Zhan Ling*, Yangyan Li, Hao Su Conference on Robot Learning (CoRL) 2022 arxiv / website / video / code / |

|
ManiSkill2: A Unified Benchmark for Generalizable Manipulation SkillsJiayuan Gu†, Fanbo Xiang†, Xuanlin Li*, Zhan Ling*, Xiqiang Liu*, Tongzhou Mu*, Yihe Tang*, Stone Tao*, Xinyue Wei*, Yunchao Yao*, Xiaodi Yuan, Pengwei Xie, Zhiao Huang, Rui Chen, Hao Su ICLR 2023 arxiv / website / code / implementation / |

|
ManiSkill: Generalizable Manipulation Skill Benchmark with Large-Scale DemonstrationsTongzhou Mu*, Zhan Ling*, Fanbo Xiang*, Derek Yang*, Xuanlin Li*, Stone Tao, Zhiao Huang, Zhiwei Jia, Hao Su Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2021 arxiv / website / video / code / implementation / |

|
Discovering Non-Monotonic Autoregressive Orderings with Variational InferenceXuanlin Li*, Brandon Trabucco*, Dong Huk Park, Yang Gao, Michael Luo, Sheng Shen, Trevor Darrell International Conference on Learning Representations (ICLR) 2021 arxiv / video_transcripts / code / poster / slides / |
|
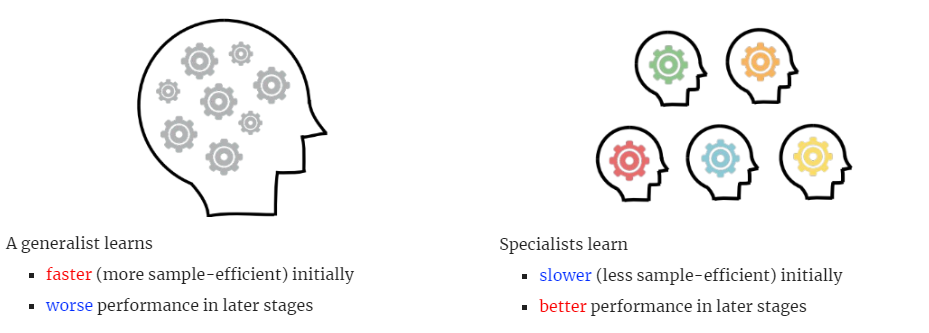
Improving Policy Optimization with Generalist-Specialist LearningZhiwei Jia, Xuanlin Li, Zhan Ling, Shuang Liu, Yiran Wu, Hao Su International Conference on Machine Learning (ICML) 2022 arxiv / website / code / |
|
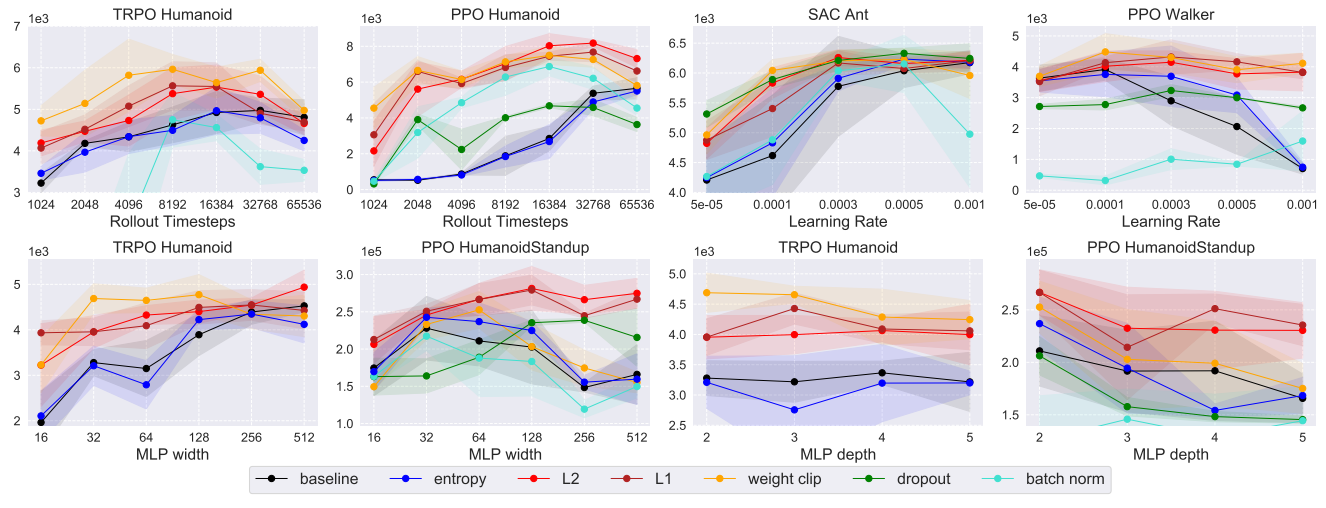
Regularization Matters in Policy Optimization - An Empirical Study on Continuous ControlZhuang Liu*, Xuanlin Li*, Bingyi Kang, Trevor Darrell International Conference on Learning Representations (ICLR) 2021 (Spotlight) arxiv / video / code / poster / slides / |
Other ProjectsThese include coursework, side projects and unpublished research work. |
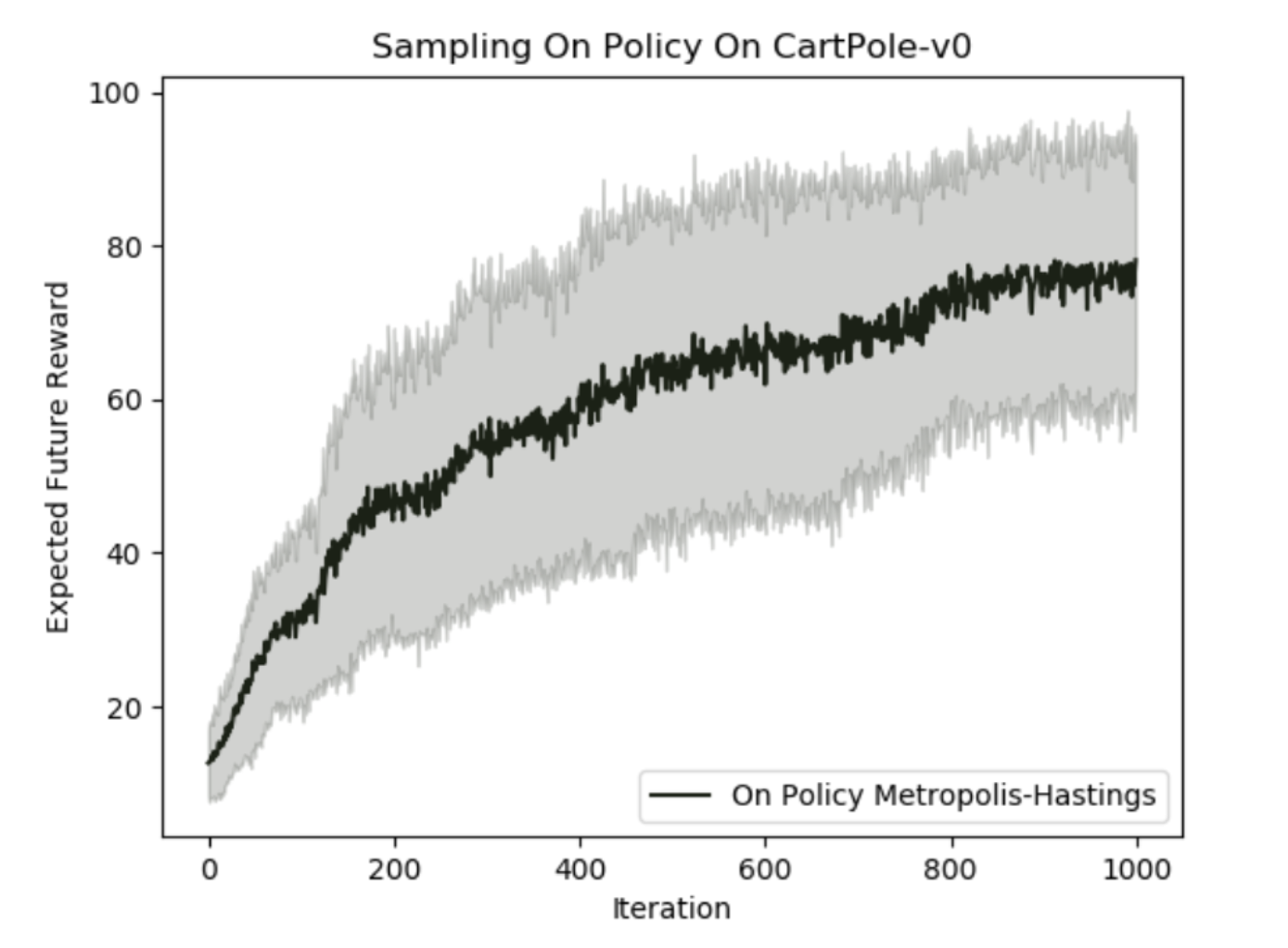
|
Inferring the Optimal Policy using Markov Chain Monte CarloBrandon Trabucco, Albert Qu, Xuanlin Li, Ganeshkumar Ashokavardhanan Berkeley EECS 126 (Probability and Random Processes) 2018-12-10 arxiv / Final course project for EECS 126 (Probability and Random Processes) in Fall 2018. |
Experiences
sudo.ai, Sep. 2024 - Now |
Services
|
Honors and Awards
Jacobs School of Engineering PhD Fellowship, UC San Diego CSE, 2021 |
|
Design and source code from Jon Barron's website |